Candidate keys:
Choosing the right primary key
It is the business that has the knowledge about their entities (things
of importance) and what kind of unique information that separate them
(invoice numbers, customer IDs, and so on).
Your role as an analyst/designer is to validate such
properties, and to fit them into a normalized database model that
reflects the needs of the business.
During this, you will discover many candidate keys and issues
concerning how they could be defined. With wrong decisions,
chances are high that you will have a worse job in normalizing the
database model, as well as achieve a high performing database in the
end. (Read the eBook on database
normalization).
).
Three absolute demands on the candidate key, if it is to be
regarded as a possible primary key.
There are three fundamental demands on the candidate key that
we
should never deviate from, if it is to become the subject for a primary
key:
- The candidate key must be unique within its domain (the
entity it represents, and beyond, if you also intend to access external
entities, with is clearly illustrated in this article).
- The candidate key can not hold NULLs
(NULL is not zero. Zero is a number. NULL is 'unknown value').
- The candidate key should never change. It must hold the
same value for a given occurrence of an entity for the lifetime of that
entity.
In 1, we say that the main purpose of the candidate key is to help us
to identify one single row in a table, regardless of whether there
exists billions of row. This sets high demands on the flexibility in
terms of delivering uniqueness.
In 2, we say that a candidate key always, without exception,
must hold a value. Without it, we break post 1.
In 3, we say that no matter what happens, inside our business
or outside of it, we are not allowed to change the value of the
candidate key. Adding an attribute (expanding) the candidate key, would
pose a change. Some say that you should be able to change the primary
key, and do a 'cascade update' to all underlying tables, ref above.
Actually, 3 it not a formal rule as such, but it is my
personal experience through the years that make me claim this as a rule
for myself, due to the limitations of today's database products.
Cascading updates are very critical operations, not well supported by
the different database system vendors.
We will deal with that in a later chapter.
If the candidate key can withstand all these three demands, we
have most likely identified our primary key.
As we proceed in this eBook, we will keep these three demands in our
minds.
You may also find interest in reading 'A Relational Model of
Data for Large Shared Data Banks' by E.F. Codd (the founder/co-founder
of the relational theory):
A
Relational Model of Data for Large Shared Data Banks
Notations in graphic examples.
Throughout this eBook, I will be using conceptual models; Entity
Relationship diagrams, as well as logical models; what is called Server
diagrams in Oracle Designer. I will also examplify the different
constructions with SELECT statements where appropriate. First, a few
words about notation in the conceptual model:
Fig. 2:
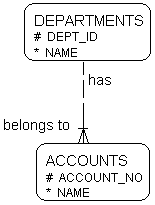
In this figure, a # in front of an attribute means the
attribute is (part of) the primary key. Likewise, the horizontal bar
over the crow-foot in the drawing of the relationship between
departments and accounts is a sign that the primary key from
departments is also a part of the primary key in the accounts entity.
How smart that is, is a totally different issue: (ACCOUNTS is breaking
2nd Normal Form: Name is dependent on ACCOUNT_NO alone, not DEPT_ID).
A * in front of an attribute signs that this attribute is
mandatory (always must have a value filled in), while an o in front of
an attribute tells that it is optional to give the attribute a value.
Likewise with the logical model:
Fig. 3:
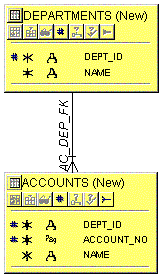
Notice the difference between the two graphics: in the logical
model in Fig.3, the relationship in Fig. 2 is incorporated in the
accounts table. The relationship in Fig. 3 now indicates that there
exists an unconditional constraint between the two tables: You are not
allowed to enter a value into DEPT_ID in accounts if it doesn't exist
in the departments table. The horizontal line above the crow-bar does
not necessarily indicate participation in the primary key of that
table: only the # tells you if a column is a part of the primary key.
By the way, Fig. numbers do not start at Fig. 1, because this is just
an excerpt from the eBook. you can check it out here: Primary
and Foreign Keys.
I have also used the plural form on entity names as well as
table names. The normal is singular form for entities, and plural for
tables. I have done this exception for reading purposes only.
Details on uniqueness
A primary key is, as stated earlier in post 1, a column, or a
collection of columns, that together give us the ability to uniquely
read one single row from a table, no matter how many rows that exists
in that table. In the logical world this is just theory, but in the
physical, we get into a lot of trouble if we are unable to do that.
Consider a simple example:
You want to give a 10% pay raise to your top DBA, John Wilson.
You do that by writing:
UPDATE EMPLOYEES
SET SALARY = SALARY * 1.1
WHERE NAME ='John Wilson';
If you have two employees with that name, they both get a pay
raise. Not exactly what you intended?
Names are very unlikely candidates for primary keys.
You need something unique, and names are not unique. Never.
Details on null values
In post 2, about no null values in a primary key: How can you
identify something you don't know? This point should go without saying,
but I bring it up, because, believe or not, I have read articles
claiming that there exists the possibility of a weak primary key;
meaning null values are allowed. Absolutely nonsense!
All meaning of the term primary key vanishes into thin air.
Most serious database systems will actually reject your attempts and
deny you to go further on that path, and with a very good reason.
If you ever come across this situation, just defy it. It is a
path of failure. Actually, it is a non-sense discussion.
Details on no change
Think about Africa. After World War II, and the end of
colonialism, how many countries have changed their names? A more recent
example: There is no longer a country called The Union of Soviet
Socialist Republics; Today we call it Russia.
We even have standards for naming countries: the former Russia
was known all over the world as USSR, and Russia is abbreviated as RUS
today (or is it?). Look at these two fantastic tables:
Fig. 4: Country definitions from the United Nations
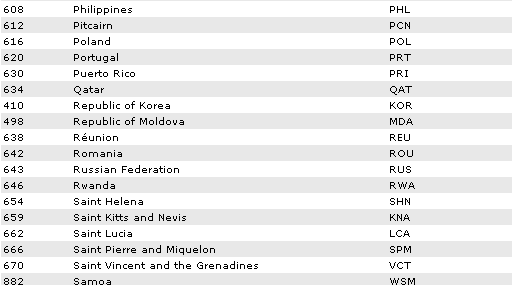
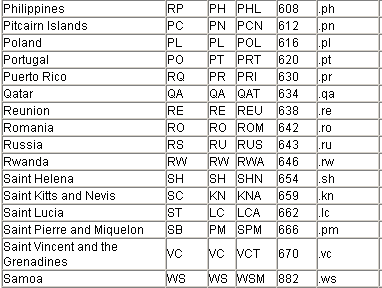
Fig:5: Another table of country definitions from the ISO
standardization organization:

Isn't that great?
Western Samoa is abbreviated WSM in the United Nations, and it
is abbreviated WS is ISO! It has even 3 identifiers in ISO; WS, WSM and
882!
Take a look at USSR (Sorry, RUS): In United Nations they call
it RUS, while ISO use RUS, RU, 643, and on Internet it's .ru. But
according to FIPS 10-4 it should be abbreviated RS! How can we identify
a country by using standards from these helpful people?
If you do a search on Google for the term 'standard country
codes' (without the quotes), you will find the sites for these two
tables among the first ten hits. Do not go to the ISO page; they
actually want you to walk around with a shopping cart and pay for it.
In fig.4, every column is a candidate key: No two countries
have the same name or any other shortcuts of the name, but they differ
all the same, if you put on a broader perspective: In ISO, the name is
Russia and the (latest determined standard) abbreviation is RU; but in
the United Nations, the name for the same country is Russian
Federation, and their abbreviation is RUS. Furthermore, in FIPS 10-4,
the abbreviation is RS. Do they never meet to talk with each other?
Looking at it isolated, all columns in Fig. 5 are also
candidate
keys. But not if you want to match entries in Fig. 4 and Fig. 5.
Actually, I can find only one common denominator here: Both
ISO and UN give Russia a common number: 643. Here is something to
investigate. Are all the other abbreviations and names meant only for
each organization, while they share the 643 number for identification?
Have they been talking to each other, after all?
It should be clear by now that we cannot rely on any of the
character columns in either organization: While each of them are
candidate keys in their own world, we would soon get into trouble if we
tried to use them to talk to all the world (that is, outside the scope
of our little application).
As you can see, defining (or choosing) the right primary keys
is not neccessarily a simple, straight-forward task.
How about another case:
You are a manufacturer, and one of your customers places an
order on behalf of his customer, asking you to use his customer's
customer number as identification: How long will it take before another
of your customers does the same, and by sheer coincidence, they supply
you with the same id (let us say cust_no 1000), but they are totally
different companies?
You will have to organize your system in such a way that you
can uniquely identify all information going into the system, regardless
of external systems, and regardless of external changes. That's the
bottom line: You have to make the primary key foolproof.
Return
to Primary and Foreign Keys
|

